Excursion to the bare-metal: ARM Cortex vs MIPS
2015-11-18 12:16 by Ian
One of the projects I did for Microchip was a feasibility study of porting the ARM Cortex instruction set to comparable routines for MIPS. The ultimate goal for the chipKIT team is/was to port the Teensy3 audio library to their line of PIC32 dev boards. What follows is my report, along with some elaborations for readers who want the knowledge, but aren't yet level 60 mages.
For those who don't know, the Teensy3 uses a Freescale microcontroller that has the Cortex-M4 instruction set. This is the origin platform. The PIC32 uses MIPS, which has a much "thinner" instruction set.
Cortex's DSP instructions are direct analogs of the x86 MMX instruction set. They are SIMD instructions that are meant to parallelize the same operation across what would otherwise be wasted register width. In Cortex's case, 16-bit integers are processed two-at-a-time via ARM's existing 32-bit registers, thereby halving the time required to run certain kinds of calculations. These are classified as DSP instructions because digital signal processing is the most common application of the calculations so accelerated.
Target boards and methodology:
The comparison was done against both the Teensy3.0 and the Teensy3.1 because the CPU in the 3.1 has a number of architectural advantages versus the CPU in the 3.0. This is the major reason for the performance gap you see in the Teensy variants, despite the Teensy3.1 being clocked at 48MHz (it's default is 72MHz).
Clock rate was eliminated as a variable for the Fubarino Mini and the Teensy boards so that their bars could be construed as the efficiency ratios between ARM and MIPS for the indicated operations. The MZ won't run that slow, so its clock rate was not adjusted. The microAptiv instruction set in the MZ was not investigated in this study. The MZ might be able to make gains beyond what is possible on the MX.
The special Cortex instructions are coded for in this file. So the porting effort will be focused here. No other changes were necessary. My (incomplete) ported version and the test apparatus is here. I'm committing some signage mistakes, so some of the multiplication fxns give incorrect results. But I believe their performance characteristics are well-represented.
Represented in the graph are all of the ARM-specific functions in-use by the Audio library. The time given is the amount of real time it took to run the function 10,000 times. So division by 10,000 will tell you how long each operation takes. There are a few reasons for this testing procedure. Since these functions execute so fast, the time-cost of the measurment skews the data in inverse-proportion to the iterations. So the first reason is to reduce measurement-induced error.
Both architectures (ARM, MIPS) and implementations (Freescale, Microchip) have features that are designed to prevent execution stalls induced by instruction-fetch from flash memory. Sometimes these features take the form of branch-prediction and instruction prefetch. But by looping the same handful of instructions as I have done, the effects of these optimizations is proportionately reduced. So the second reason is to mitigate the effect of instruction access-time on the measurement.
Since these tests were conducted inside of the broader Arduino/chipKIT framework, there are interrupts and unsummoned code that might run periodically on one platform or the other. I have tried to eliminate this effect entirely, but by running for many iterations, we proportionately reduce the effect of these resource-diversions to the extent that they escaped my attention (if at all).
Adjusting the iteration count revealed an absurdly low statistical variation in the results (standard deviation of ~1uS). So I take these results to be faithful representations of the things being measured.
Data:
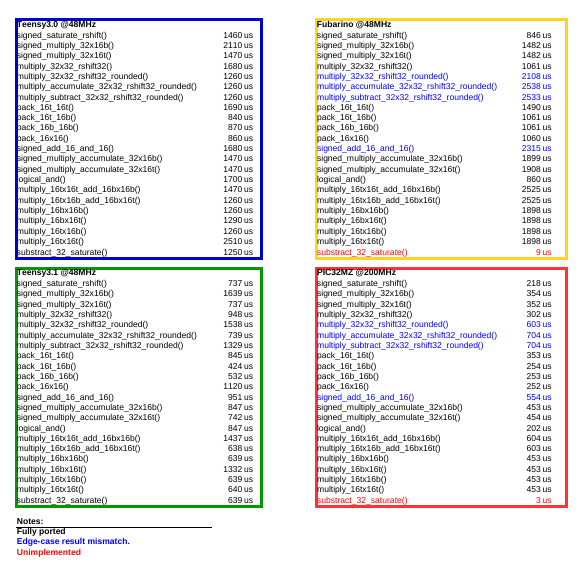
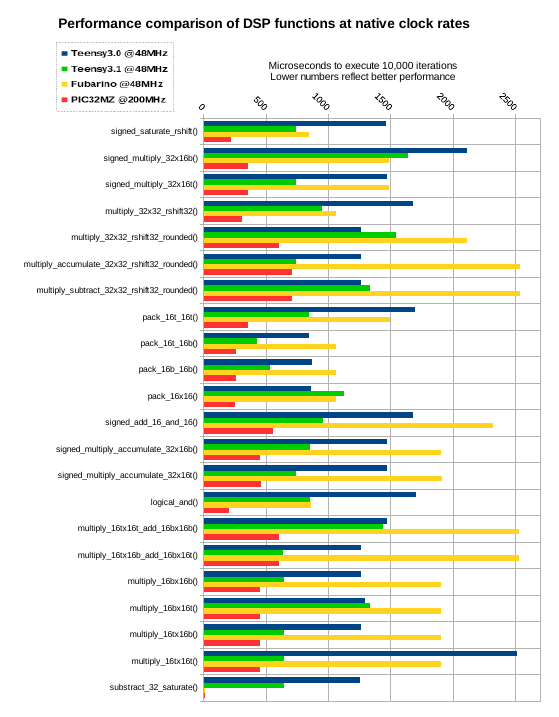
Observations:
The MIPS M4K instruction set has a lovely instruction called INS. INS is what is allowing the PIC32 to get such flat response over the pack() instructions. Logical AND is at parity.
// computes (a[31:16] | b[15:0])
static inline uint32_t pack_16t_16b(int32_t a, int32_t b) __attribute__((always_inline, unused));
static inline uint32_t pack_16t_16b(int32_t a, int32_t b) {
//asm volatile("pkhtb %0, %1, %2" : "=r" (out) : "r" (a), "r" (b));
uint32_t out;
asm volatile("addi %0, %1, 0x00000000 \n \
ins %0, %2, 0x00, 0x10" : "=r" (out) : "r" (a), "r" (b));
return out;
}
// computes ((a[15:0] << 16) | b[15:0])
static inline uint32_t pack_16b_16b(int32_t a, int32_t b) __attribute__((always_inline, unused));
static inline uint32_t pack_16b_16b(int32_t a, int32_t b) {
//asm volatile("pkhbt %0, %1, %2, lsl #16" : "=r" (out) : "r" (b), "r" (a));
uint32_t out;
asm volatile("andi %0, %2, 0x0000ffff \n \
ins %0, %1, 0x10, 0x10" : "=r" (out) : "r" (a), "r" (b));
return out;
}
// computes ((a[15:0] << 16) | b[15:0])
static inline uint32_t pack_16x16(int32_t a, int32_t b) __attribute__((always_inline, unused));
static inline uint32_t pack_16x16(int32_t a, int32_t b) {
//asm volatile("pkhbt %0, %1, %2, lsl #16" : "=r" (out) : "r" (b), "r" (a));
uint32_t out;
asm volatile("andi %0, %2, 0x0000ffff \n \
ins %0, %1, 0x10, 0x10" : "=r" (out) : "r" (a), "r" (b));
return out;
}
The multiply and accumulate instruction was instrumental in attaining the performance of many of the multiplication routines. Combined with the double-wide accumulator, many of the ARM instructions can be emulated with very little penalty.
Conclusions, and opinions regarding future porting efforts:
16-bit multiplication performance is flat, but about 50% worse in the worst-case versus the Freescale part. It looks like MIPS is going to make up for it when both operands are 32-bit. I'm able to use some clever tricks because of the 64-bit accumulator. I'm able to pull only half the result where I know the other half would be discarded. The multiply and shift instructions are going to be painful where the shift is not an even 32-bit boundary. This and the 16x16 +/- 16x16 instructions are going to be the biggest differential.
Despite the fact that MIPS is at the disadvantage for these specific cases, it can be nothing more than PR hype for all but a very specific breed of engineer attacking a specific class of problem: One that involves lots of 16-bit integer arithmetic that doesn't care much about overflows. And even then, I've never used a compiler that is smart enough to "see the intent" behind a programmer's (usually unoptimized) arithmetic in C, and leverage those instructions. Paul Stoffregen (the author of the Teensy Audio libraries) explains the situation nicely here:
“The honest truth of the Cortex-M4 DSP instructions is they take quite a bit of planning and work to use properly. ARM doesn't say that in their marketing materials, but unless you want a specific math operation that's already optimized in a library, you have a lot of work to do.
You have to surround them with code that brings pairs of 16 bit samples into 32 bit words. This effectively doubles the register storage, and it lets you take advantage of the M4's optimized load and store of successive 32 bit words, and reduced looping overhead. Some of the operations are very convenient too, like multiplying 16 * 32 bits for a 48 bit result, and then discarding the low 16 bits, which consumes only a single 32 bit register for the output.
Optimizing code with these instructions is all about planning how many registers will hold inputs and output and other stuff. It's very low-level stuff requiring quite a lot of thinking about registers and clock cycles. You can get quite a bit of speedup this way, but it's not simple or easy. It's quite a lot of work to optimize code. Many parts of the library are written to leverage these instructions. The FIR filter and FFT from ARM's math lib use them, and I used them in many places in the library like the biquad filter, noise generators, state variable filter, mixer, etc.
There's no simple and easy way to automatically use the DSP instructions. It's always involves lot of careful planning and optimization work. “
As an example of why good pipe-lining is a better route to fast code than special instructions, notice my translation of this function....
// computes limit((val >> rshift), 2**bits)
static inline int32_t signed_saturate_rshift(int32_t val, int bits, int rshift) {
//asm volatile("ssat %0, %1, %2, asr %3" : "=r" (out) : "I" (bits), "r" (val), "I" (rshift));
int32_t out = (val >> rshift);
uint32_t pow = (1 << bits) - 1;
return ((((int32_t)pow) > out) ? out : pow);
}
I couldn't do any better than the compiler. So I left it as C. And that is one of the functions that exhibits better efficiency on MIPS. This is a tremendous advantage because it means that the architecture is good enough that a compiler can produce better-running code from several general instructions than can a CPU with the instruction baked into the silicon. The former requires very little skill or care to see benefits, and the super-fancy DSP instruction requires a level 60 mage that really cares.
Considering that many of the MX parts in the chipKIT line run at 80MHz, the ported functions will likely run better-than or on-par with the Teensy boards. The Teensy3.0 would need to be overclocked to 96MHz to keep up, and even so, probably wouldn't even come close to MIPS efficiency for straight-up multiplication. The presence of that high-word result register makes a huge difference to both the compiler and to the mages that inhabit the land of assembly.
The route to faster libraries:
Given that the pack() instructions are usually a first step to using the rest of the DSP instructions, they are basically useless on MIPS. That arch has no need of them. So if I were to port the Audio lib to MIPS, I would find every place where those functions were used and I would choose those places to start rewriting things in a different manner that may be more appropriate for any arch. For the case of the MZ, I would convert the audio samples to floats as soon as DMA shuffled them in and pass them to the filter classes as floats. Then I would re-translate back to integer formats for output over i2s or whatever else.
Reason #1: By using a human-native number format, programs are more comprehensible because the use of more-direct translations of abstract mathematical formulae avoid the need for the author to tie his reasoning into an integer-shaped pretzel. That, with little-to-no loss of performance (because MIPS is intelligently pipe-lined, and the FPU is a co-proc).
Reason #2: By promoting the samples to a 32-bit type, your 16-bit (or 24-bit) input samples are processed through a data-path that doesn't suffer from aliasing, quantization noise created by filters and effects, or any other artifact that is induced when 5 divided by 3 is equal to 1.
This point is belabored in the commentary of the Audio library where carefully-planned trade-offs have been made. Distortions in signal power (>5%) or higher noise-floors are common prices paid in the filter classes for the sake of being able to run on low-speed hardware.
Strengths of the PIC32 parts that stand out:
When talking about the realm of the serious hobbyists and RToS crowd that demand the fastest chips that won't run linux, cost-per-unit-compute becomes very important. The MZ is $11 and has almost twice the RAM versus the $20 ST part at roughly the same capabilities (FPU, 215MHz, 320KB RAM). The fact that the MZ's FPU is double-wide is a unique feature in this market. There are a number of high-precision applications for which the MZ is a perfect (and cheap) option.
Chaining DMA without even causing interrupts is a really neat trick. It isn't easy on the STM32 unless it is planned for at the time the PCB is being designed, Otherwise, software would be involved at some point. Even if it was just to ping an ISR. The MZ doesn't even demand that. This lends itself to all manner of applications where high-bandwidth i/o is required.
By the datasheets, the MZ at 200MHz has one-fewer wait-states for flash access (if I remember correctly) versus the STM32F4 at 168MHz. And because its instruction set isn't 150+ instructions (like Cortex-M is), it can load more instructions-per-clock.
This is a big deal because my coding style is not kind to branch-prediction logic. I sometimes re-code hot-spots to take advantage of those features of a CPU, but I know that most people do not, and wouldn't know how. Therefore, a benchmark that was intentionally abusive of branch prediction would make the PIC line look very nice. A real-world application that would cause such loads would be asynchronous event queues and callbacks. Careless use of C++ virtual functions also have a tendency to invalidate branch-prediction.
A real-world engineering choice considering these issues:
Manuvr's data glove is an example of a non-audio case where the extra instructions might be worth paying attention to. I do a fair amount of multiplication on 16-bit integers, since that is the native data type the sensors return. Also, like most audio applications, overflow isn't possible. Even so, there are two reasons I don't use any of the DSP instructions in the Cortex-M4.
A) If my chain of arithmetic for the data in the glove is 100 operations long, only the first 13 or so are able to take advantage of the DSP instructions because the following 87 are floating point. Integers aren't soaking up the juice. Float is.
B) The DSP instructions are most-useful in cases where either the data being operated on stays in-register for several iterations of similar instructions, or is stored in memory in a very careful manner so as to minimize the need of pack()-like operations to prepare the data to be fed into an SIMD instruction. This is the purpose of pack().
Audio typically fits at least one of these criteria. IMU data does not. Even so, I would have made the effort to use the instructions if there was a co-proc relationship between the CPU and the DSP instructions. But because there isn't in the Cortex-M, I don't get the pipe-lining benefit of using special instructions, but I would still get all of the headaches.
Historical anecdote (x86)
Remember MMX2/3DNow/SSE1-4? Astoundingly few programs ever use any of that stuff, even today where those special instructions are widely supported. But all that specialized gear requires transistors that take power and die area. After ~20 years of the instruction-set marketing war between AMD and Intel, AMD is leaving the x86 market, Intel abandons the NetBurst arch due to clock-chain power consumption in order to pipeline all that special gear, and the world starts migrating to ARM, which doesn't carry all the burden of back-compat for the instruction sets that 97% of code-in-use doesn't use.
MIPS and ARM are both designed to have co-processors bolted onto a very general CPU with a minimal instruction set. I gather that MIPS has been more fastidious about holding to a RISC philosophy, but I have less XP with MIPS than I do with ARM.
ARM's co-proc slots are used for purposes other than instruction sets, but the fact that they forked their base instruction set (Cortex-M is one of the DSP variants, and is not implemented as a co-proc) is occasionally a nightmare. There must be a good reason they did this, but I cannot imagine it.
NEON (which is a co-proc) was a much better-conceived (and better-executed) idea, IMO. It does the same sort of thing that Cortex-M does, but is much more capable, is much wider (128 vs 32-bits), and (most importantly) has an independent execution unit, thus lending itself to both good pipelining as well as better power-management.
To put the experience into a metaphor closer to everyday experience, NEON feels like this:

Cortex-M feels like this:

Ever had a guy with a gun-mounted flashlight point it at you without thinking because he was using his flashlight (which also happened to be a gun) to see you talking to him? Need to be able to pipeline those two tools...
Ok... so Cortex gives you a knife too. How many people have ever needed to stab a guy while shooting him?
1 guy per 326,235. That's how many.
But EVERYONE using Cortex pays for the knife.
Previous: C++ Style choices (notes)
Next: Open ports are not a security hole