C++ Style choices (notes)
2015-06-20 22:20 by Ian
This is an entry from the Manuvr Blog that I am cross-posting here.
This post is aimed at programmers-in-general, and covers some general stylistic perspectives. The vehicle is C++, but the stylistic issues at hand are experienced by programmers in basically every language of which I'm aware. Except Whitespace. Those guys have no issues with style. :-)
I would be the last person to jump down anyone's throat for off-center style practices. In fact, I consider style quirks (my own and others) to be one of my most useful touchstones when learning new code. Moreover, I try to be a stylistic chameleon when working in new code. So please don't construe this post as recommendations or an invitation to a holy war, but rather as a report of what I've tried, liked, and collected after programming computers for the past 20 years.
80-column limits
Unless I would be wrecking the style integrity of already-existing code, I have no qualms about writing an if() conditional that is 300 characters long. Obviously, this makes it harder to translate code into this sort of medium, and it occasionally drives (even me) bananas when I need to debug such a conditional, but the thing it saves is indentation confusion, split-line slashes, and a false sense of simplicity.
Update 2024.07.23:
I have changed my thinking about this. For the past six years or so, I've begun using column justification as a loose visual proxy for complexity that is intended to avoid those 300 character conditionals which seem to frustrate everyone but me. It also has minor advantages for scope control and constant-time code. Below is a contrived sample of this pattern.
bool isPowerOfTwo(uint32_t x) {
const bool ONE_OR_FEWER_ZEROS = (x & (x - 1));
const bool IS_NONZERO = (x > 0);
return (IS_NONZERO & ONE_OR_FEWER_ZEROS);
}
Soft versus hard tabs
I go back-and-forth on this. And that is evident from the trail of tabs I've left behind me on github. These days, I'm preferring soft tabs with a width of 2 spaces. I have no reasons for preferring this, which is why I'm back-and-forth. Typically, I'll use whatever tabbing mode is already extant in the source file.
Update 2024.07.23:
I've changed my mind. Hard-tabs render like trash and interfere with block-mode editing. If there is no one to complain about it, I'll bulk-replace every hard-tab in a file as soon as I notice them. I've been consistent in this regard since the original writing, so I doubt I'm going back.
Explicit integer sizes
Call it a bias induced from writing embedded programs for more than half my life, but I don't want to have to wonder if my unsigned int will end up as a uint32 or a uint64. The difference is highly material, and there is an unholy amount of code (some of it mine) that will break when such an assumption is not met. If you write for multiple architectures, you can quickly (and silently) break fragile code that you didn't even write. Any cases where the compiler is left free to change the width of integers is a potential source of bugs that may not surface for decades. I'm not joking when I say I've found bugs of this sort that were written prior to the breakup of Yugoslavia and "worked on my machine" until 2015.
Type auto is blacklisted
If I wanted soft types, I'd use javascript. Type auto wrecks the ability to understand the data a program operates upon. Sometimes to the point of obscuring the entire program underneath layers of complex types that are then concealed behind type inference.
void makeDennisRitchieCry(uint8_t x) {
auto obj = getMyObject();
auto splines = obj->transformStepCount(x);
obj->reticulate(*splines);
}
Type auto is used by people in too big of a hurry, or to paper-over an absence of better discipline elsewhere. Even a typedef would save you from aphasia.
// If your type reads like this, you have deeper issues with your program. // Not even the author will remember this reliably in 36-hours, and it is useless // as instructive code. std::map<std::string, std::vector<SnowflakeType<float, float, float>>>*
Superfluous parentheticals
If you passed algebra, you almost certainly don't need to be reminded of the order of operations. And those same algebra rules apply inside the compiler. IE....
int x = 6 + 1 * 3;
...is always equal to 9, and there is no ambiguity. But what if you see this?
int n = x * x + y * y + z * z;
I don't know about you, but I distrust my ability to read that accurately all the time. So I would make my meaning explicit so it is immediately clear that I intend to add the squares of those terms...
int n = (x * x) + (y * y) + (z * z);
It is worth noting that when thinking about order-of-operations with Boolean algebra, many people use a translation-layer in their knowledge that looks like this....
Ok... so... "a & b | c" means "a * b + c", therefore I need to "a & (b | c)".
This is common because most of us learned order-of-ops WAY earlier than Boolean algebra. And Boolean algebra was probably presented to us with our decimal algebraic knowledge as a base.
Even if you innately know that there is no difference between AND and multiplication, it still doesn't address any of this....
int a = p | r ^ s & q; // PEMDAS is incomplete. auto b = (float) 2 * (double) PI; // How much of PI got discarded (if any)? uint64_t c = y << 51; // ...with k being an (int8).
The issue is too technical for this post, but floating point addition is not commutative, and has several other quirks which take many years to fully understand. But suffice it to say, that sometimes paranthesis that appear superfluous might actually be telling the compiler to coerce a type (or not) in a way that it wouldn't have otherwise. This is especially true for people who like to do this...
if (x) { someFxn(); }
...rather than this...
if (0 != x) { someFxn(); }
Too much parenthetical delineation is better (IMO) than chasing down bugs resulting from a human being misunderstanding such things.
If you still think I use too many parentheses, please take this image and go show it to someone who you believe knows algebra:
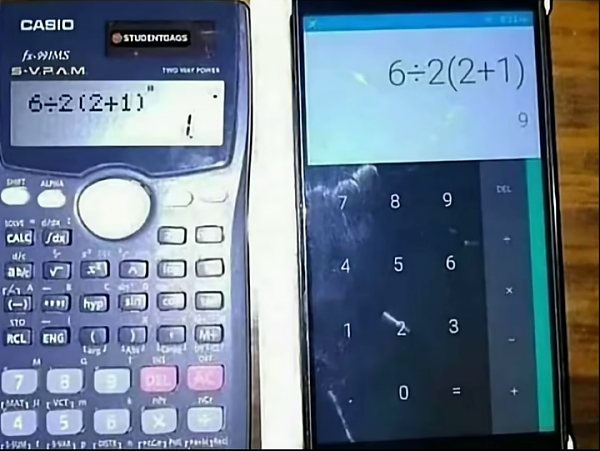
Superfluous delineation of scope
Python programmers can ignore this, as their language prevents the problem depicted here.
I prefer a flavor of K&R, with indentation strictly reflecting scope. But that is barely important. What is important is that there always be braces following a conditional. Lots of code out there looks like this...
if (x) do_something();
Or worse...
if (x) do_something();
In all but very narrow circumstances, I will always rewrite this to be...
if (x) {
do_something();
}
...because on more occasions than I can count, I have encountered (or myself written) bugs like this...
if (x) do_something(); do_something_else_afterward();
The rare occasion that I let myself be THAT lazy is this one...
if (verbosity > 1) local_log.concat("Unexpected return case.");
The intention here is to only print that log line. Nothing else should depend on that conditional. In that case, the whole line could be sensibly replaced by a macro without risking the bug.
If you haven't caught onto the theme of my style choices yet, notice that they are typically geared toward reducing human error.
It might also be worth noting that C/C++ programmers often use } as their garbage collection.
This is only half snark. Consider this sort of function, where a large amount of memory is allocated to arrive at a result that is small, and then never used again.
void someFunction(){
float big_array[128000];
collect_data(big_array);
float result = calculate_median_value(big_array);
notify_for_result(result); // This might be long-running.
render_result(result); // ...do something else that you need to do afterward.
}
The stack memory occupied by big_array will be held for the entire runtime of notify_for_result(result), and it would be for no good reason. So things that might look to a novice like superfluous scope may actually be memory-management measures which will radically change program performance if collapsed:
void someFunction(){
float result;
{
// For my part, I try to always leave a comment that this empty scope matters.
float big_array[128000];
collect_data(big_array);
result = calculate_median_value(big_array);
} // This line tells GCC that it can relinquish part of the stack.
notify_for_result(result); // This might be long-running.
render_result(result); // ...do something else that you need to do afterward.
}
Artful omission of break;
This is related to "stacking case labels", and underscores a programmer that values tight-code over clarity.
I'm not always disciplined about it, but if I have code like this that not only stacks case labels, but also has more than a few lines of intervening code, I will try to notate it to indicate that...
- it was not an oversight, and
- care should be exercised nearby
Avoidance of assignment while testing for equality
From StringBuilder....
/*
* Thank you N. Gortari for the most excellent tip:
* // Null-checking is a common thing to do...
* Intention: if (obj == NULL)
*
* // Compiler allows this. Assignment always evals to 'true'.
* The risk: if (obj = NULL)
*
* // Equality is commutative.
* Mitigation: if (NULL == obj)
*
* "(NULL == obj)" and "(obj == NULL)" mean exactly the
* same thing, and are equally valid.
*
* Leverage assignment operator's non-commutivity,
* so if you derp and do this...
* if (NULL = obj)
* ...the mechanics of the language will prevent compilation,
* and thus, not allow you to overlook it on accident.
*/
void StringBuilder::prependHandoff(StringBuilder *nu) {
if (NULL != nu) {
this->root = promote_collapsed_into_ll();
StrLL *current = nu->promote_collapsed_into_ll();
if (NULL != nu->root) {
// Scan to the end of the donated LL...
while (NULL != current->next) { current = current->next; }
current->next = this->root;
this->root = nu->root;
nu->root = NULL;
}
}
}
Subverting linguistic rules with type-casting
To achieve certain kinds of OO design patterns in C (not C++), programmers will frequently cast and type-pun to avoid re-writing code. See this.
I think that this reeks of duress, but sometimes it is the best thing to do. Here are some reasons people do it...
- When the reason for casting is to avoid a harmless linguistic granularity (Casting to-and-from volatile or [sometimes] const)
- C has no function overrides. So without doing this, we would also need to write a second void some_fxn(SomeOtherDataType)*, thus repeating ourselves. Not only do we repeat ourselves in our source code, but we also repeat the same machine code in the binary.
- It is expedient. And it is often a graceful segue into a proper type strategy.
Type-casting might also be used in arithmetic to ensure proper integer alignment, and so forth. But if I find myself type-casting under any circumstance not listed above, I start questioning my own judgement.
Short-circuit evaluation
There are non-trivial efficiency gains from using this....
boolean marked_complete = markComplete();
if (err_state || !marked_complete) {
report_failure();
}
...versus this (note the short-circuit)...
boolean marked_complete = markComplete();
if (err_state | !marked_complete) {
report_failure();
}
That's great. But what if you carelessly code this...
if (err_state || !markComplete()) {
report_failure();
}
Your intention might have been to always call markComplete(), regardless of err_state. But that is not what will happen. If your err_state evals to 'true', the short-circuit will drop out before doing the thing you thought was unconditional. The quick solution is to take advantage of the fact that OR is commutative...
if (!markComplete() || err_state) {
report_failure();
}
I love encapsulating my fxn calls into conditionals in this way. So I am at particular risk of creating this bug. I've found no stylistic means of catching myself (other than not using fxn calls inside of compound conditionals). So I simply stay vigilant.
Update 2024.07.23:
Since I wrote this post a decade ago, I have encountered many good reasons to not use short-circuit evaluation at all. These days, I basically only use it for null-checking objects ahead of accessing them...
if ((nullptr != ref) && (0 != ref->someFxn())) {
report_failure();
}
The issue is: Depending on your execution environment and purpose, you might want to write code that uses as few branches as possible (or none at all). Short-circuit eval involves a conditional branch, and your efforts to save cycles might open a security exploit. Constant-time code is also beneficial in hardware environments where you need to keep execution tightly-locked to a cadence of events in the real-world. In such cases, you might sensibly choose to blacklist short-circuit from a codebase.
It might also be worth noting, that short-circuit costs an extra 4-bytes of code size on ARM32 thumb. And execution-in-place (XiP) arrangements in some platforms might actually bottle-neck at code-read. So by eschewing short-circuit, and saving 4-bytes of flash and a branch, your code might actually run faster, despite what your computer science professor taught you.
All of this applies equally to ternary assignments. When you feed this into GCC, it will produce a conditional branch, along with all of the side-effects that implies.
uint32_t same_var = (some_condition) ? 5 : 2;
Anecdote:
I recently led a firmware team for a product that needed to have constant-time performance for large sections of its codebase, and was based on a XiP architecture. Teaching people how to constrain timing in their programs is always difficult. Teaching them how to do it on XiP turned out to be impossible. They ended up releasing their product without understanding how it worked because I could not convince their engineering manager to spend the time to clean up what he probably saw as meaningless style gripes. Hidden behavior from ternaries and short-circuits cost that team many man-weeks of pointless struggle.
Inlining accessor members
I see nothing but benefit by doing things like this.
Update 2024.07.23:
I watched a particularly stubborn engineer struggle with inline and section placement. His code kept dragging product performance down and even crashing it under certain conditions. He had tried to inline an entire ring buffer implementation to avoid having to specifically place it with a linker script, and GCC silently refused to comply. He figured that because he had marked it inline, GCC would "just do it". But there are a number of reasons why GCC might choose to ignore your inline qualifiers. So keep them short.
I consider explicit inline of functions to be FAR superior to macros because a macro happens at the pre-processor (prior to the compiler). And the pre-proccessor has no type checks. Which leads me to....
Macros
Here is a good SO post on the pitfalls of macros. Mats Petersson's answer pretty much sums up my thoughts on macros. I do use them occasionally, but this is pushing the boundaries of good taste (and is on-deck for refactor due to type ambiguity)...
#ifndef max #define max( a, b ) ( ((a) > (b)) ? (a) : (b) ) #endif #ifndef min #define min( a, b ) ( ((a) < (b)) ? (a) : (b) ) #endif
I would, however, consider platform abstraction to be a generally-acceptable use of macros...
#ifndef STM32F4XX
// To maintain uniformity with ST's code in an non-ST env...
#define I2C_Direction_Transmitter ((uint8_t)0x00)
#define I2C_Direction_Receiver ((uint8_t)0x01)
#define IS_I2C_DIRECTION(DIRECTION) (((DIRECTION) == I2C_Direction_Transmitter) || \
((DIRECTION) == I2C_Direction_Receiver))
#endif
A note regarding tool-choices and graphanalysis
I refuse to use an auto-formatter. I do all of my programming in a glorified text-editor (JEdit / Atom / TextPad) with no auto-complete and no auto-formatting. The one exception to this is java, where I will use Eclipse or IntelliJ for the sake of using the other tools surrounding the Java (Android layout editor, ADB front-end, etc).
Why would I be so masochistic?
- Tools that engender dependency are very dangerous tools.
- I consider this to be perfect legible commentary. Feed it into the autoformatter of your choice, and watch it become illegible. Tools that are easy-to-use and wreck perfectly good information are very dangerous tools.
- Buried in this class's whitespace are strong clues to its phylogeny.
That last point is subtle. But here is a simple example. Take this comment block, and contrast it with this one. Notice that they are different widths. There are a number of reasons this might be the case. But considering that the flavor of the block is the same, the most likely is that the same author is using another (already extant) class as fodder for copy-pasta. A fuzzier version of the same conclusion could be drawn from hard vs soft tabbing that is intermixed in the same file; Either several authors, or a passage of time touched this file between edits.
If I were hunting a bug, I could then use that whitespace difference to find the functional boundaries of the edits, and looks for mistakes on the interface. Either the authors were not aware of how the other thought (if there were really two authors), or the same author let too many moons pass, and then dove into a feature addition with an insufficient re-read of his own code. Any experienced programmer who is honest with vimself realizes that he has done both.
After all... whitespace is part of the code, and I can only assume that the person who put it there did it for a reason (if if that reason was "copy-paste").
I've been trying to convert all of my commentary into a format that Doxygen can parse and use. But to use an autoformatter to achieve that end on someone else's code is wrecking perfectly good information that (if you are a detail-oriented reader) would help you better understand the program, and not merely the code.
Update 2026.01.02:
After reading some of my old code, I realized that I should probably mention why there isn't usually any do (as in: do-while) in my code....

StrLL* src_ll = _root; // Iterator over the source list.
while (nullptr != src_ll) {
// Do things...
src_ll = src_ll->next;
}
Previous: Data structures (Priority queues)
Next: Excursion to the bare-metal: ARM Cortex vs MIPS